Atera – Spatial data with single-cell resolution
![]()
In this tutorial, we will explore how scCellFie can be run on the latest spatial technology from 10X Genomics (Atera). This tutorial should be also compatible with other spatial technologies with single-cell resolution covering the whole transcriptome such as Visium HD.
Here, we will use the preview data published by 10X Genomics for Breast Cancer.
This tutorial includes following steps:
Loading libraries
[1]:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import sccellfie
from sccellfie.io import read_xenium, load_xenium_segmentation
from sccellfie.datasets import load_sccellfie_database
from sccellfie.expression.thresholds import get_sccellfie_dataset_threshold
from sccellfie.reports import generate_completeness_report
from sccellfie.plotting import plot_segmentation
import scanpy as sc
/Users/eg22/miniforge3/envs/single_cell/lib/python3.10/site-packages/dask/dataframe/__init__.py:31: FutureWarning: The legacy Dask DataFrame implementation is deprecated and will be removed in a future version. Set the configuration option `dataframe.query-planning` to `True` or None to enable the new Dask Dataframe implementation and silence this warning.
warnings.warn(
In addition, we set up the folder where the Atera data bundle (output of Xenium Ranger) is located:
[2]:
DATA_DIR = "/Users/eg22/RNAseq-Data/Atera-FFPE-Breast-Cancer/"
Loading Atera data
The bundle is expected to contain at minimum cell_feature_matrix.h5, cells.csv.gz, and cell_boundaries.parquet.
read_xenium reads the cell-feature matrix, joins centroids from cells.csv.gz, and (when present) attaches analysis/clustering/gene_expression_graphclust/clusters.csv as adata.obs['cluster']. Centroids land in adata.obsm['X_spatial'] — the scCellFie convention.
[3]:
adata = read_xenium(DATA_DIR, segmentation="cell")
adata
Note: /Users/eg22/RNAseq-Data/Atera-FFPE-Breast-Cancer/analysis/clustering/gene_expression_graphclust/clusters.csv not found, skipping cluster attachment.
[3]:
AnnData object with n_obs × n_vars = 170057 × 18028
obs: 'cell_id', 'transcript_counts', 'control_probe_counts', 'genomic_control_counts', 'control_codeword_counts', 'unassigned_codeword_counts', 'deprecated_codeword_counts', 'total_counts', 'cell_area', 'nucleus_area', 'nucleus_count', 'segmentation_method'
var: 'gene_ids', 'feature_types', 'genome'
obsm: 'X_spatial'
Loading cell polygons
We then load the cell segmentation resulting from running Xenium Ranger. Here, we apply the function load_xenium_segmentation, which returns a {cell_id: shapely.Polygon} dict ready for the function plot_segmentation in scCellFie v0.6.0. The cell IDs must match adata.obs_names, so in case you changed them in your data, you will need to adjust the IDs in the keys of this dictionary to match your data.
[4]:
seg = load_xenium_segmentation(f"{DATA_DIR}/cell_boundaries.parquet", output="dict")
print(f"Loaded {len(seg)} polygons")
Loaded 170057 polygons
QC Metrics
We use the scanpy functions to evaluate different metrics of the Atera data:
[5]:
sc.pp.calculate_qc_metrics(adata, percent_top=(10, 20, 50, 150), inplace=True)
OMP: Info #276: omp_set_nested routine deprecated, please use omp_set_max_active_levels instead.
[6]:
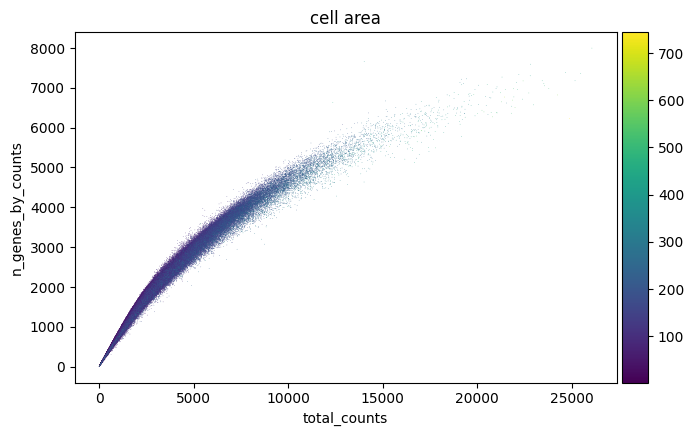
sc.pl.scatter(adata, "total_counts", "n_genes_by_counts", color="cell_area")
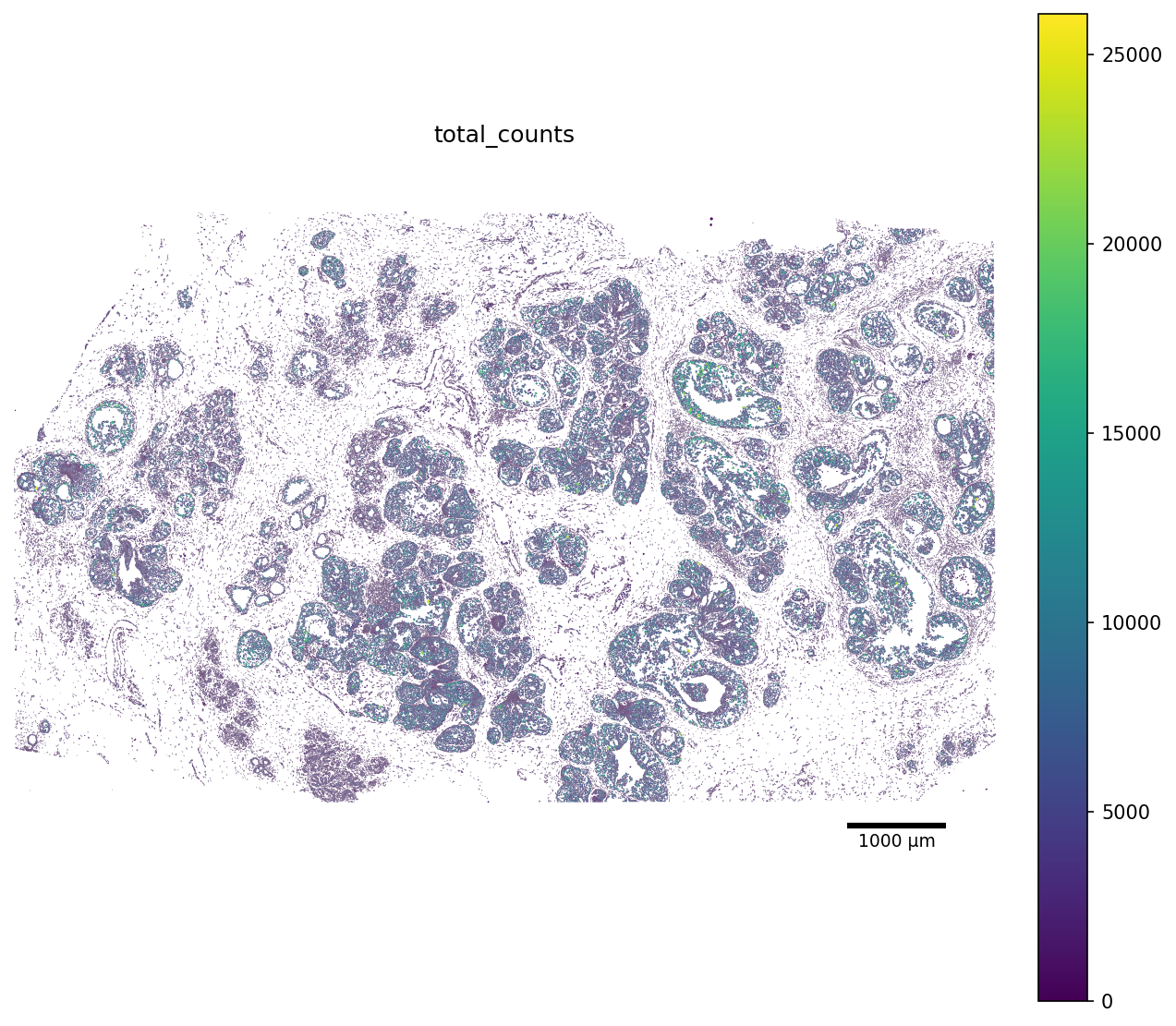
We can also render every cell as its segmentation polygon, coloured by the total_counts metric. For this purposes, scCellFie includes a convinient plot_segmentation function.
[7]:
color_by = "total_counts"
fig, ax = plot_segmentation(
adata,
segmentation=seg,
color_by=color_by,
figsize=(10, 10),
scalebar_kwargs={"units": "µm"},
)
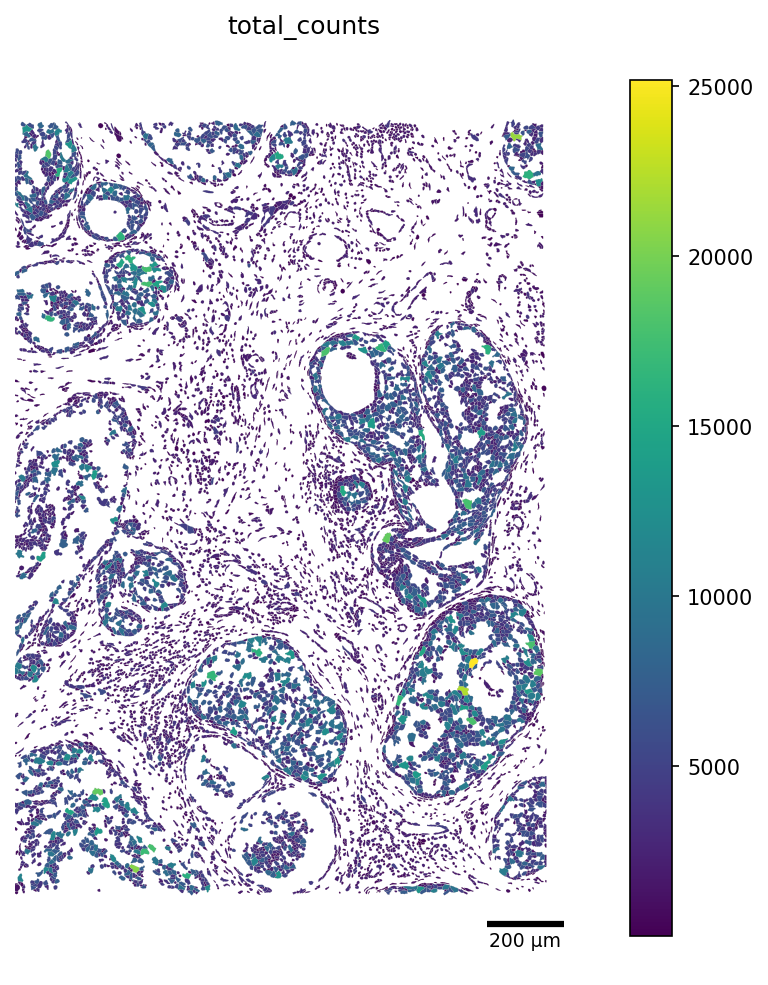
Additionally, we can crop our visualization window by picking a rectangular region of the slide. The window is in the same coordinate units as adata.obsm['X_spatial'] (microns for Xenium).
Adjust crop to a region of interest. The window below displays a default 1500-µm by 2000-µm selection box, with X-axis limits of 8500-10000 and Y-axis limits of 1500-3500.
[8]:
crop_window = (8500, 1500, 10000, 3500)
fig, ax = plot_segmentation(
adata,
segmentation=seg,
color_by=color_by,
crop=crop_window,
figsize=(8, 8),
scalebar_kwargs={"units": "µm"},
)
Preprocessing
Now that we have a general idea of our data, we can apply some basic filtering.
[9]:
min_counts_cell = 100
min_genes = 10
min_counts_gene = 20
min_cells = 20
target_sum = 10000
[10]:
sc.pp.filter_cells(adata, min_counts=min_counts_cell)
sc.pp.filter_cells(adata, min_genes=min_genes)
sc.pp.filter_genes(adata, min_counts=min_counts_gene)
sc.pp.filter_genes(adata, min_cells=min_cells)
Then, normalize and log-transform the data.
[11]:
adata.layers['counts'] = adata.X.copy()
sc.pp.normalize_total(adata, target_sum=target_sum, inplace=True)
sc.pp.log1p(adata)
scCellFie Data preparation
Data completeness
Before running scCellFie, we need to understand how complete is our data in term of genes that are covered in the DB of metabolic tasks used in the analysis.
In this case, scCellFie conveniently incorporates a generate_completeness_report functions that answers two questions:
Dataset-level: which genes / reactions / tasks from the metabolic database are even measurable on this assay (i.e. present in
adata.var_names)?Cell-level: per cell, how complete is each task given the genes that are present and expressed (>0)?
The dataset-level answer is computed on the full slide.
We first load the DB we will use in the analysis, in this case we use the one already included in scCellFie:
[12]:
db = load_sccellfie_database(organism='human')
gpr_strings = db["rxn_info"].set_index("Reaction")["GPR-symbol"].to_dict()
Then, we generate the report:
[13]:
report = generate_completeness_report(
adata,
gpr_source=gpr_strings,
task_by_rxn=db["task_by_rxn"],
metric="fraction_zeroed",
threshold=1.0,
layer='counts',
write_to_obs=True,
)
This function generates the following reports:
Dataset-level views
report[“dataset”][“task_completeness”] # which tasks are well-supported?
report[“dataset”][“reaction_completeness”] # which reactions specifically?
report[“dataset”][“overall_summary”] # one-line headline numbers
Cell-level views
report[“cell”][“per_cell”] # one score per cell (essential + all)
report[“cell”][“matrix_essential”] # includes info about essential genes
report[“cell”][“matrix_all”] # includes info about all genes in the DB
We can check how the dataset-level completeness look like:
[14]:
overall = report["dataset"]["overall_summary"]
overall
[14]:
| n_tasks_total | n_tasks_fully_covered_essential | n_tasks_fully_covered_all | n_tasks_compromised_essential | n_tasks_compromised_all | mean_task_impact_weighted_essential | mean_task_impact_weighted_all | mean_task_fraction_present_essential | mean_task_fraction_present_all | n_reactions_total | n_reactions_fully_covered_essential | n_reactions_fully_covered_all | n_genes_in_db_total | n_genes_in_db_present_in_adata | fraction_db_genes_present | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 218 | 216 | 139 | 2 | 60 | 0.990826 | 0.93844 | 0.994393 | 0.957514 | 787 | 755 | 737 | 931 | 879 | 0.944146 |
The columns of this dataframe are:
Column |
Meaning |
|---|---|
|
Number of tasks in |
|
Tasks where |
|
Tasks where |
|
Tasks where |
|
Tasks where |
|
Mean of per-task essential impact-weighted completeness. |
|
Mean of per-task all-scope impact-weighted completeness. |
|
Mean of per-task |
|
Mean of per-task |
|
Number of reactions. |
|
Reactions where |
|
Reactions where |
|
Distinct genes across the whole GPR database. |
|
Of those, how many your assay measures. |
|
Ratio of the previous two (1.0 if database is empty). |
[15]:
# Top tasks ranked by impact-weighted completeness over essential genes
task_completeness = report["dataset"]["task_completeness"]
task_completeness.sort_values("impact_weighted_completeness_essential",
ascending=False).head(15)
[15]:
| n_genes_essential | n_present_essential | n_missing_essential | fraction_present_essential | impact_weighted_completeness_essential | total_impact_missing_essential | missing_genes_essential | n_genes_all | n_present_all | n_missing_all | fraction_present_all | impact_weighted_completeness_all | total_impact_missing_all | missing_genes_all | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Task | ||||||||||||||
| (R)-3-Hydroxybutanoate synthesis | 0 | 0 | 0 | 1.0 | 1.0 | 0.0 | 29 | 29 | 0 | 1.000000 | 1.000000 | 0.000000 | ||
| Sialylation (addition of sialic acid) | 0 | 0 | 0 | 1.0 | 1.0 | 0.0 | 2 | 2 | 0 | 1.000000 | 1.000000 | 0.000000 | ||
| Presence of the thioredoxin system through the thioredoxin reductase activity | 1 | 1 | 0 | 1.0 | 1.0 | 0.0 | 1 | 1 | 0 | 1.000000 | 1.000000 | 0.000000 | ||
| Proline degradation | 0 | 0 | 0 | 1.0 | 1.0 | 0.0 | 94 | 91 | 3 | 0.968085 | 0.955882 | 0.044118 | PAICS;SLC25A6;TALDO1 | |
| Proline synthesis | 0 | 0 | 0 | 1.0 | 1.0 | 0.0 | 28 | 28 | 0 | 1.000000 | 1.000000 | 0.000000 | ||
| Proteasome degradation | 0 | 0 | 0 | 1.0 | 1.0 | 0.0 | 37 | 35 | 2 | 0.945946 | 0.333333 | 0.666667 | PSMA5;PSMD7 | |
| Pyridoxal-phosphate synthesis | 1 | 1 | 0 | 1.0 | 1.0 | 0.0 | 1 | 1 | 0 | 1.000000 | 1.000000 | 0.000000 | ||
| Reactive oxygen species detoxification (H2O2 to H2O) | 1 | 1 | 0 | 1.0 | 1.0 | 0.0 | 1 | 1 | 0 | 1.000000 | 1.000000 | 0.000000 | ||
| Recognition of misfolded protein | 0 | 0 | 0 | 1.0 | 1.0 | 0.0 | 11 | 11 | 0 | 1.000000 | 1.000000 | 0.000000 | ||
| Retro-translocation & substrate ubiquitination | 0 | 0 | 0 | 1.0 | 1.0 | 0.0 | 31 | 31 | 0 | 1.000000 | 1.000000 | 0.000000 | ||
| S-adenosyl-L-methionine synthesis | 0 | 0 | 0 | 1.0 | 1.0 | 0.0 | 3 | 3 | 0 | 1.000000 | 1.000000 | 0.000000 | ||
| Serine degradation | 0 | 0 | 0 | 1.0 | 1.0 | 0.0 | 97 | 81 | 16 | 0.835052 | 0.166667 | 0.833333 | ATP5F1E;ATP5PB;CYTB;ND1;ND2;ND3;ND4;ND4L;ND5;N... | |
| Serine synthesis | 0 | 0 | 0 | 1.0 | 1.0 | 0.0 | 20 | 20 | 0 | 1.000000 | 1.000000 | 0.000000 | ||
| Sphingomyelin synthesis | 0 | 0 | 0 | 1.0 | 1.0 | 0.0 | 225 | 201 | 24 | 0.893333 | 0.734940 | 0.265060 | ACSL6;AK2;ATP5F1E;ATP5PB;COX1;COX2;COX3;COX6A1... | |
| 3'-Phospho-5'-adenylyl sulfate synthesis | 0 | 0 | 0 | 1.0 | 1.0 | 0.0 | 2 | 2 | 0 | 1.000000 | 1.000000 | 0.000000 |
Task completeness and reaction completeness dataframes include similar information of each of them:
Column |
Meaning |
|---|---|
|
Number of essential genes for this task. |
|
Of those, how many are in |
|
How many are absent from |
|
|
|
Raw sum of |
|
|
|
|
|
Total number of genes appearing in any reaction of this task. |
|
Of those, how many are in |
|
How many are absent from |
|
|
|
Raw sum of |
|
|
|
|
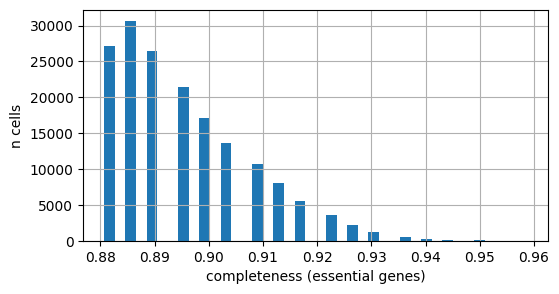
Similarly, we can check the completeness at a cell-level. First we inspect the essential genes:
[16]:
# Distribution of per-cell completeness (essential-gene scope) across the slide
fig, ax = plt.subplots(figsize=(6, 3))
adata.obs["completeness_essential"].hist(bins=40, ax=ax)
ax.set_xlabel("completeness (essential genes)")
ax.set_ylabel("n cells")
plt.show()
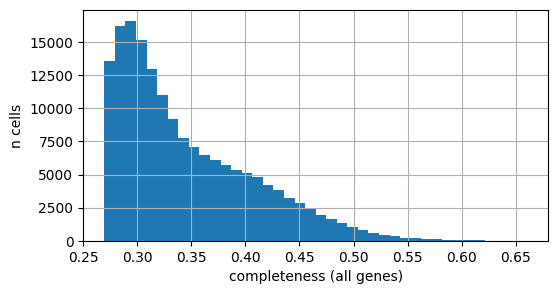
And all the genes in the DB:
[17]:
# Distribution of per-cell completeness (all-gene scope) across the slide
fig, ax = plt.subplots(figsize=(6, 3))
adata.obs["completeness_all"].hist(bins=40, ax=ax)
ax.set_xlabel("completeness (all genes)")
ax.set_ylabel("n cells")
plt.show()
Gene expression thresholds for computing metabolic scores
A core step of the scCellFie’s workflow is using threshold values to determine whether a metabolic gene may be active or not. As indicated in the scCellFie publication, we can compute the threshold of each metabolic gene by using gene expression at an atlas scale (e.g. the human cell atlas). However, the Atera technology is quite recent so there is no atlas-scale data available, covering the full difersity of cells in the human body. Therefore, the full range of Atera-level expression for each of the metabolic genes is not available.
For this reason, here we rely only on the gene expression levels found within the slide. Normally, we compute a threshold value as the mean value of the non-zero CP10K expression levels, clipped to the 25th and 75th expression percentiles across all metabolic genes as lower and upper boundaries. In this case, we will adapt this approach to make each activity to be meaningful relatevely to cells within the slide:
To compute the thresholds, we can use the get_sccellfie_dataset_threshold function, which streams the AnnData in chunks and computes a per-gene threshold using by default the same rule as in the scCellFie manuscript (clip(nonzero_mean, P25, P75)). It returns a single-column DataFrame consumable by run_sccellfie_pipeline via threshold_key.
This is run on within the slide so the percentiles reflect the slide’s true expression distribution. Here, instead of using as boundaries the 25th and 75th percentiles, we use the 10th and 40th percentiles as the lower and upper boundaries.
Note!
You can personalize the thresholds as you prefer to compare activities within the slide. It is important to consider that this example may misrepresent the activity of some tasks as the threshold values are computed in a dataset-wise manner rather than an atlas-wise manner, which may lead to overall low/high activity of some of the tasks when they should behave differently.`
[18]:
thresholds = get_sccellfie_dataset_threshold(
adata,
organism='human',
lower_percentile=10,
upper_percentile=40,
layer='counts',
verbose=True,
)
thresholds.head()
Streaming chunks: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:03<00:00, 1.53s/it]
[18]:
| sccellfie_threshold | |
|---|---|
| symbol | |
| A4GALT | 2.807018 |
| A4GNT | 2.807018 |
| AAAS | 2.807018 |
| AACS | 2.807018 |
| AADAC | 2.807018 |
Run scCellFie
To illustrate the use of scCellFie on Atera data, we will focus on a cropped version of the data, facilitating its visualization. Here, we will use the same crop window as in the preprocessing step.
[19]:
xmin, ymin, xmax, ymax = crop_window
coords = adata.obsm["X_spatial"]
mask = (
(coords[:, 0] >= xmin) & (coords[:, 0] <= xmax) &
(coords[:, 1] >= ymin) & (coords[:, 1] <= ymax)
)
adata_crop = adata[mask].copy()
print(f"Cropped from {adata.n_obs} -> {adata_crop.n_obs} cells")
Cropped from 168870 -> 11239 cells
Additionally, we override the database’s default 'sccellfie_threshold' column with the dataset-specific values we just computed by injecting them into a copy of db and passing it via sccellfie_db=....
[20]:
db_custom = dict(db)
db_custom["thresholds"] = thresholds # column name is 'sccellfie_threshold' by default
We arrange the data to have the raw counts in the adata.X slot:
[21]:
adata_crop.layers['log1p'] = adata_crop.X.copy()
adata_crop.X = adata_crop.layers['counts'].copy()
Now we run scCellFie on the raw data.
[22]:
results = sccellfie.run_sccellfie_pipeline(
adata_crop,
organism='human',
sccellfie_db=db_custom,
threshold_key="sccellfie_threshold",
smooth_cells=False, # turn on if you want KNN smoothing
n_counts_col="total_counts", # cells.csv.gz already provides this
disable_pbar=False,
verbose=True,
)
==== scCellFie Pipeline: Initializing ====
Loading scCellFie database for organism: human
==== scCellFie Pipeline: Processing entire dataset ====
---- scCellFie Step: Preprocessing data ----
---- scCellFie Step: Preparing inputs ----
Gene names corrected to match database: 22
/Users/eg22/Library/CloudStorage/GoogleDrive-eg22@sanger.ac.uk/Shared drives/VenTo_Lab/Erick/Projects/Metabolic-Tasks/scCellFie/sccellfie/preprocessing/adata_utils.py:151: UserWarning: Normalizing data.
warnings.warn("Normalizing data.", UserWarning)
/Users/eg22/Library/CloudStorage/GoogleDrive-eg22@sanger.ac.uk/Shared drives/VenTo_Lab/Erick/Projects/Metabolic-Tasks/scCellFie/sccellfie/gene_score.py:74: ImplicitModificationWarning: Setting element `.layers['gene_scores']` of view, initializing view as actual.
adata.layers[layer] = gene_scores
Shape of new adata object: (11239, 879)
Number of GPRs: 775
Shape of tasks by genes: (217, 879)
Shape of reactions by genes: (775, 879)
Shape of tasks by reactions: (217, 775)
---- scCellFie Step: Computing gene scores ----
---- scCellFie Step: Computing reaction activity ----
Cell Rxn Activities: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 11239/11239 [00:25<00:00, 442.80it/s]
---- scCellFie Step: Computing metabolic task activity ----
Removed 1 metabolic tasks with zeros across all cells.
==== scCellFie Pipeline: Processing completed successfully ====
Note!
run_sccellfie_pipeline filters the AnnData against the database (drops genes/reactions/tasks not measurable on this assay) and returns the filtered object inside results['adata']. The .reactions and .metabolic_tasks attached AnnDatas live on that returned object — not on the original adata_crop you passed in. We assign the result to adata_scored in the next cell.
To access metabolic activities, we need to inspect results['adata']:
The processed single-cell data is located in the AnnData object
results['adata'].The reaction activities for each cell are located in the AnnData object
results['adata'].reactions.The metabolic task activities for each cell are located in the AnnData object
results['adata'].metabolic_tasks.
In particular:
results['adata']: contains gene expression in.X.results['adata'].layers['gene_scores']: contains gene scores as in the original CellFie paper.results['adata'].uns['Rxn-Max-Genes']: contains determinant genes for each reaction per cell.results['adata'].reactions: contains reaction scores in.Xso every scanpy function can be used on this object to visualize or compare values.results['adata'].metabolic_tasks: contains metabolic task scores in.Xso every scanpy function can be used on this object to visualize or compare values.
Other keys in the results dictionary are associated with the scCellFie database and are already filtered for the elements present in the dataset ('gpr_rules', 'task_by_gene', 'rxn_by_gene', 'task_by_rxn', 'rxn_info', 'task_info', 'thresholds', 'organism').
[23]:
adata_scored = results['adata']
print('cells x scored genes:', adata_scored.shape)
print('reactions:', adata_scored.reactions.shape)
print('metabolic_tasks:', adata_scored.metabolic_tasks.shape)
cells x scored genes: (11239, 879)
reactions: (11239, 775)
metabolic_tasks: (11239, 216)
We can rank the metabolic tasks by their mean expression across the slide:
[24]:
task_means = pd.Series(
np.asarray(adata_scored.metabolic_tasks.X.mean(axis=0)).ravel(),
index=adata_scored.metabolic_tasks.var_names,
)
task_means.sort_values(ascending=False).head(5)
[24]:
Task
Conversion of 1-phosphatidyl-1D-myo-inositol 4,5-bisphosphate to 1D-myo-inositol 1,4,5-trisphosphate 3.746275
Biosynthesis of Tn_antigen (Glycoprotein N-acetyl-D-galactosamine) 2.018268
Conversion of carnosine to beta-alanine 1.676080
Fructose degradation (to glucose-3-phosphate) 1.531106
AMP salvage from adenine 1.522179
dtype: float64
Visualizations
scCellFie now incorporates functions to visualize metabolic scores in the space, but this time by using the cell segmentations. When cell segmentations are missing, it will simply plot a cell as a dot, whose size is controlable with the parameter scatter_size.
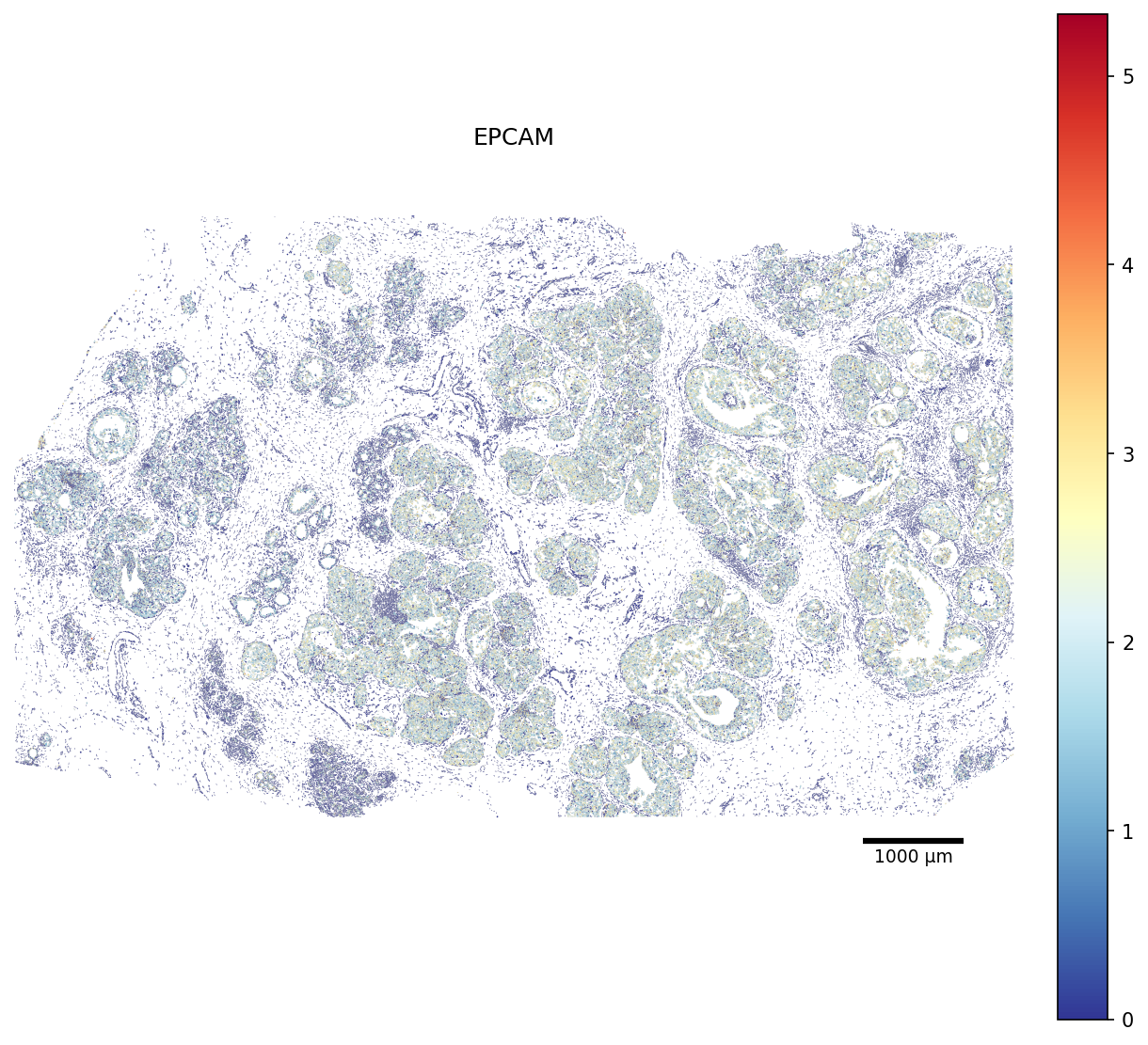
Here we plot the EPCAM gene first from the gene expression values so locate the epithelial cells in the tissue (full slide):
[25]:
# Restrict the polygon dict to the scored cells (faster rendering)
seg_crop = {cid: seg[cid] for cid in adata.obs_names if cid in seg}
fig, ax = plot_segmentation(
adata,
segmentation=seg_crop,
color_by='EPCAM',
cmap='RdYlBu_r',
figsize=None,
scalebar_kwargs={'units': 'µm'},
)
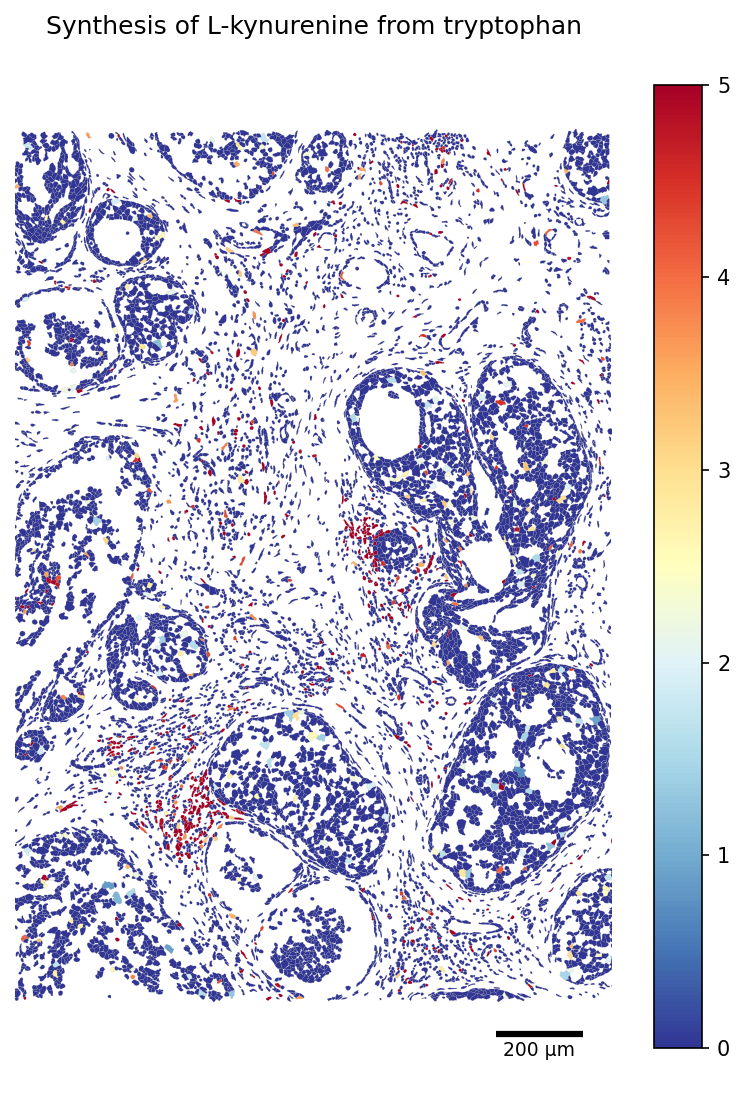
Then, we plot one of the metabolic tasks that have previously been link to multiple cancers (cropped slide):
[26]:
TASK = 'Synthesis of L-kynurenine from tryptophan'
# Restrict the polygon dict to the scored cells (faster rendering)
seg_crop = {cid: seg[cid] for cid in adata_scored.obs_names if cid in seg}
fig, ax = plot_segmentation(
adata_scored.metabolic_tasks,
segmentation=seg_crop,
color_by=TASK,
cmap='RdYlBu_r',
figsize=(9, 9),
vmax=5,
scalebar_kwargs={'units': 'µm'},
)
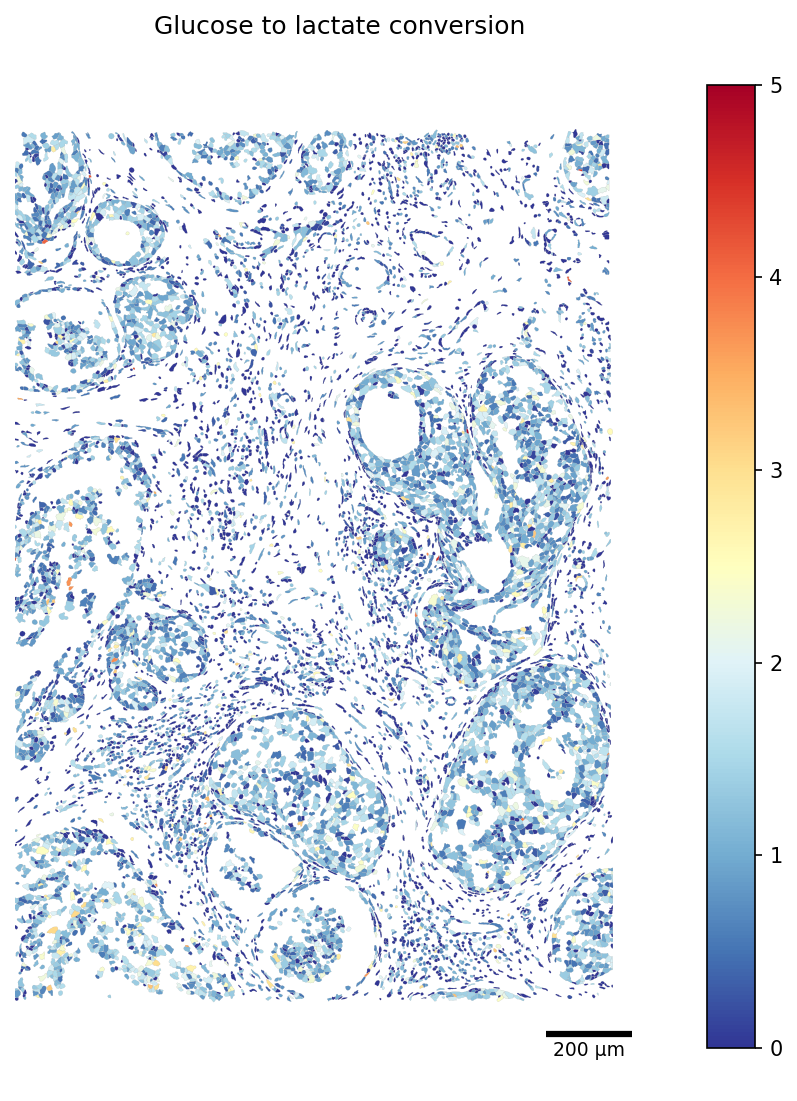
Similarly, we visualize the production of lactate, a hallmark of multiple cancers:
[27]:
TASK = 'Glucose to lactate conversion'
# Restrict the polygon dict to the scored cells (faster rendering)
seg_crop = {cid: seg[cid] for cid in adata_scored.obs_names if cid in seg}
fig, ax = plot_segmentation(
adata_scored.metabolic_tasks,
segmentation=seg_crop,
color_by=TASK,
cmap='RdYlBu_r',
crop=crop_window,
figsize=(9, 9),
vmax=5,
scalebar_kwargs={'units': 'µm'},
)
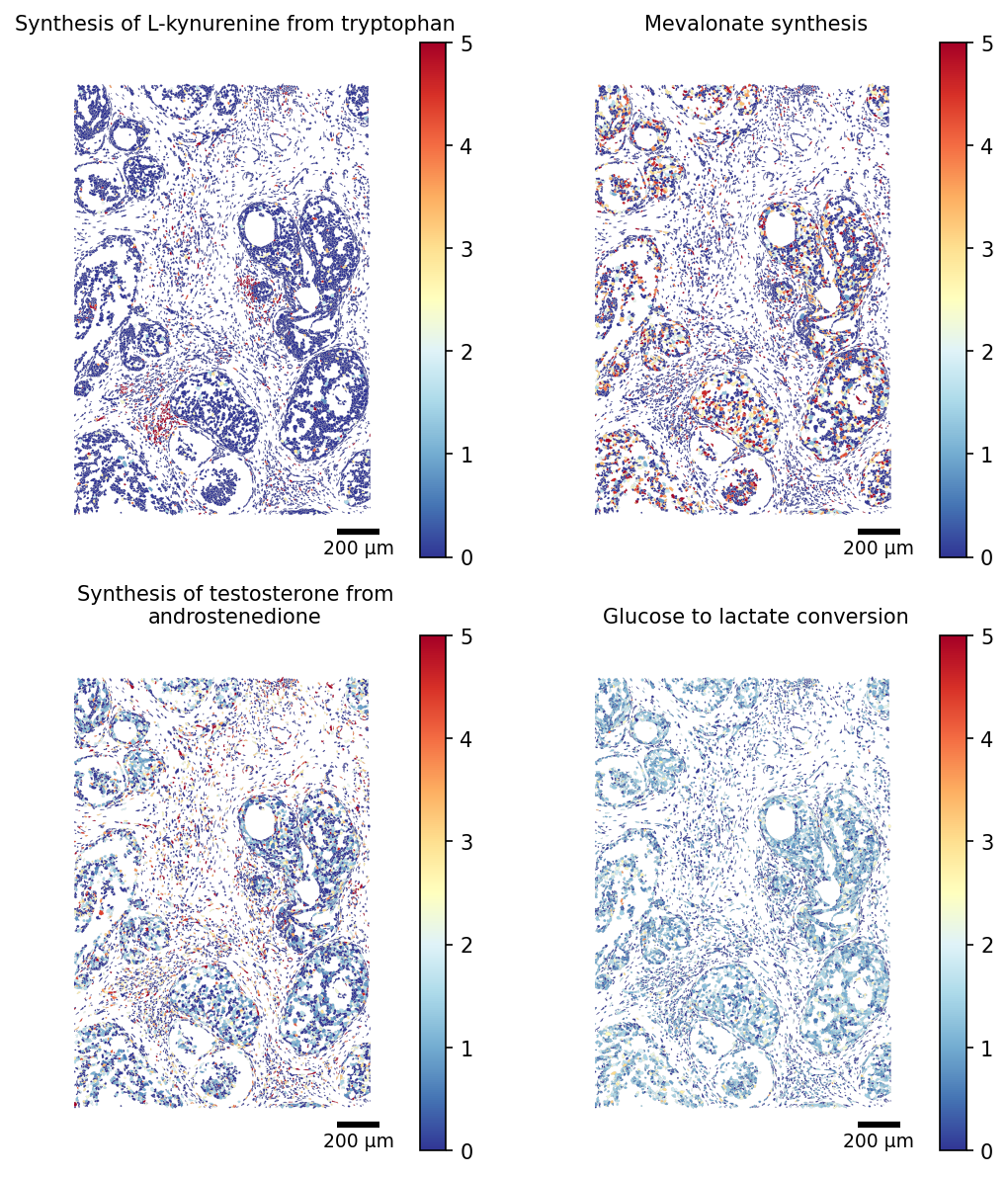
the scCellFie function further supports the visualization of multiple tasks, where we can control the number of columns by modifying the parameter ncols.
[28]:
TASKS = ['Synthesis of L-kynurenine from tryptophan', 'Mevalonate synthesis',
'Synthesis of testosterone from androstenedione', 'Glucose to lactate conversion']
# Restrict the polygon dict to the scored cells (faster rendering)
seg_crop = {cid: seg[cid] for cid in adata_scored.obs_names if cid in seg}
fig, ax = plot_segmentation(
adata_scored.metabolic_tasks,
segmentation=seg_crop,
crop=(8500, 1500, 10000, 3500),
color_by=TASKS,
cmap='RdYlBu_r',
figsize=(4,4),
ncols=2,
scalebar_kwargs={'units': 'µm'},
vmax=5,
title_fontsize=10,
)